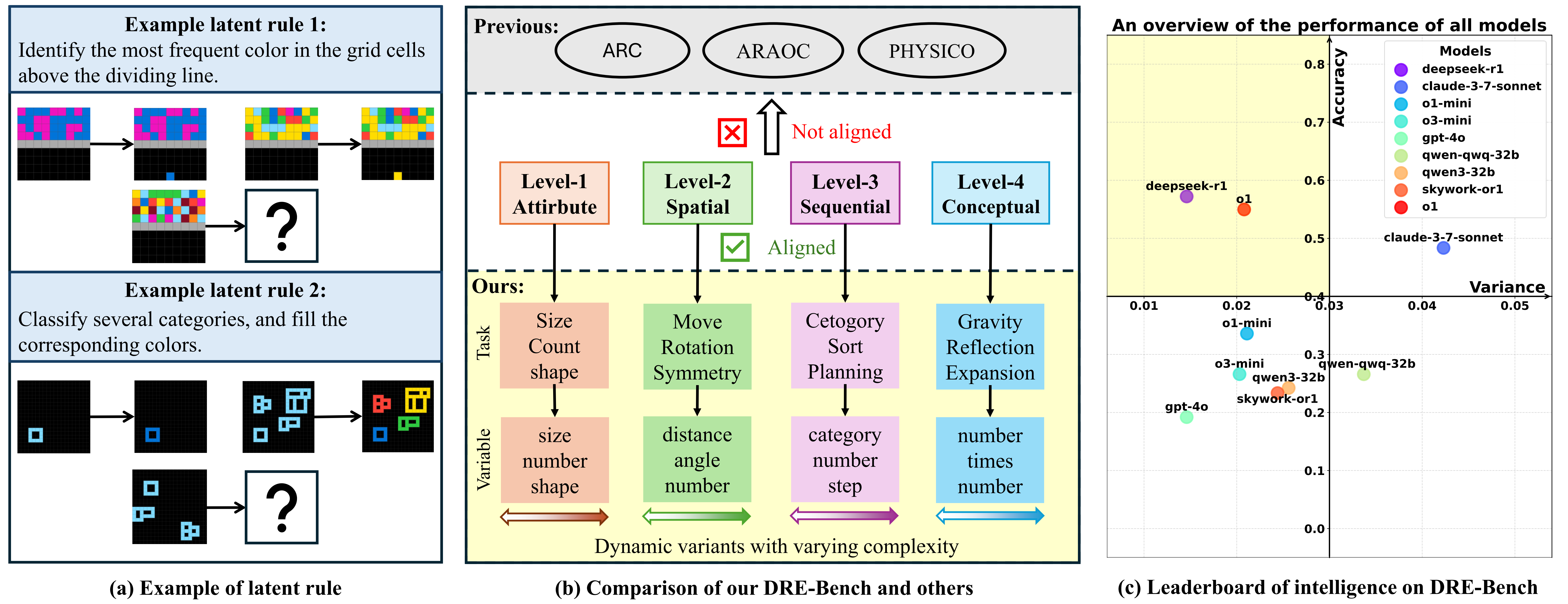
Recent advances in large language models (LLMs) have demonstrated impressive reasoning capacities that mirror human-like thinking. However, whether LLMs possess genuine fluid intelligence (i.e., the ability to reason abstractly and generalize rules in novel situations) remains an open question. Existing reasoning benchmarks either focus on domain-specific knowledge (crystallized intelligence) or lack interpretability. To address these limitations, we propose DRE-Bench, a dynamic reasoning evaluation benchmark grounded in a hierarchical cognitive framework. DRE-Bench consists of 36 abstract reasoning tasks organized across four cognitive levels, with each task featuring multiple dynamic variants that test the same underlying latent rule. This design enables fine-grained, interpretable, and reliable assessments of fluid intelligence. We evaluate a range of state-of-the-art LLMs, including both general LLMs (GPT-4o, Claude 3.7) and reasoning LLMs (o1, DeepSeek-R1, QwQ, Skywork-OR1). Experimental results reveal that although most LLMs achieve competent and robust performance in low-level cognition, they struggle with high-level cognition and exhibit limited generalization as task complexity grows. Our findings highlight the gap between current LLMs and true human-like fluid intelligence and offer a new path for systematically tracking reasoning progress in LLMs.
the contributions of this paper are summarized as follows. 1) We propose an abstract reasoning benchmark with a cognition hierarchy, providing a more structural and comprehensive system to analyze the LLMs' true fluid intelligence. 2) We develop a verifiable and scalable data engine to dynamically generate abstract reasoning data with various complexities, by designing a generator and solver for each task. 3) We perform comprehensive evaluations on a variety of popular LLMs, indicating that the existing LLMs still struggle to solve the reasoning problem of high cognitive levels. Existing LLMs may not have truly internalized the underlying reasoning rules, which highlights that they remain far from achieving true fluid intelligence.
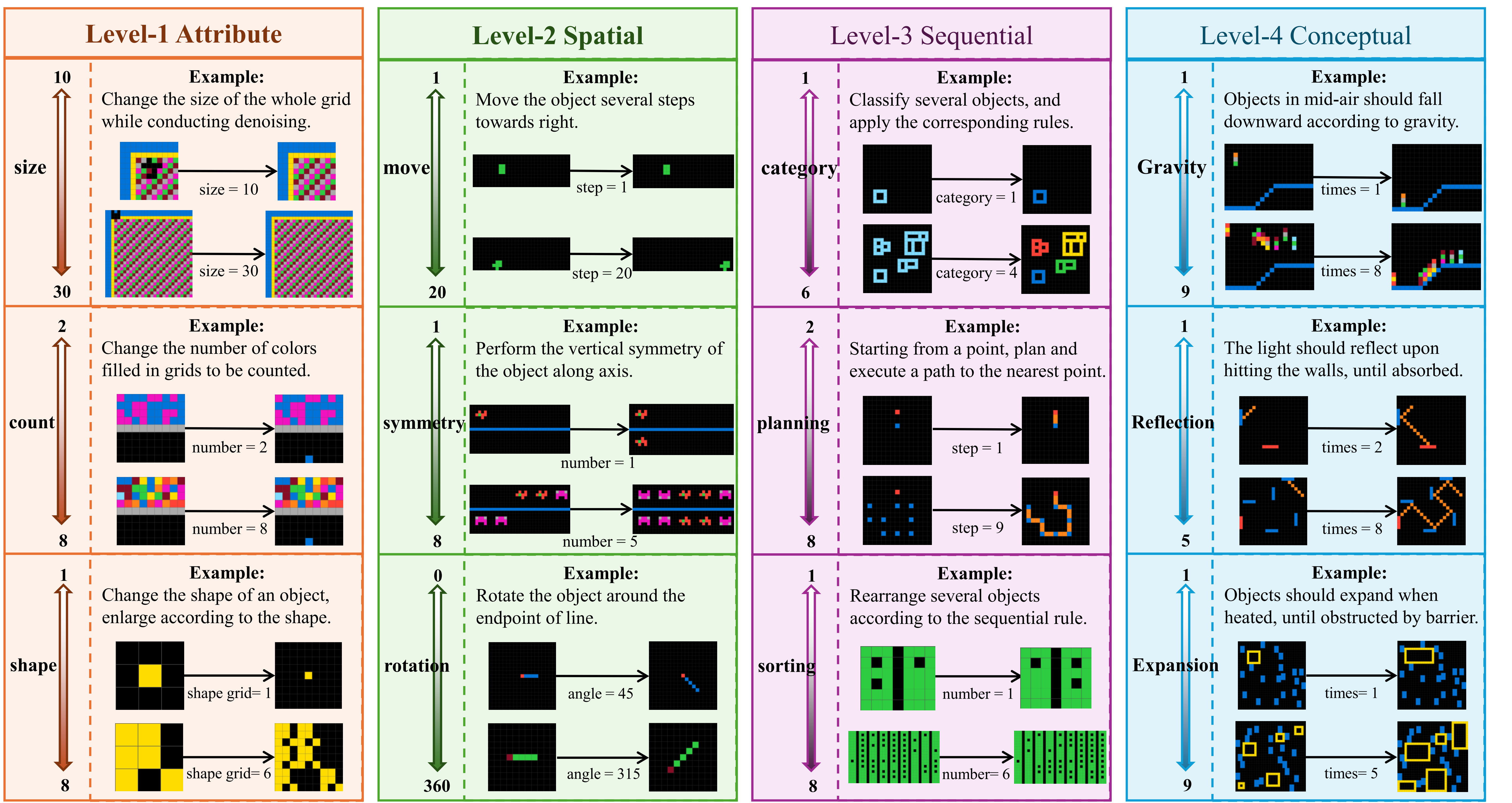

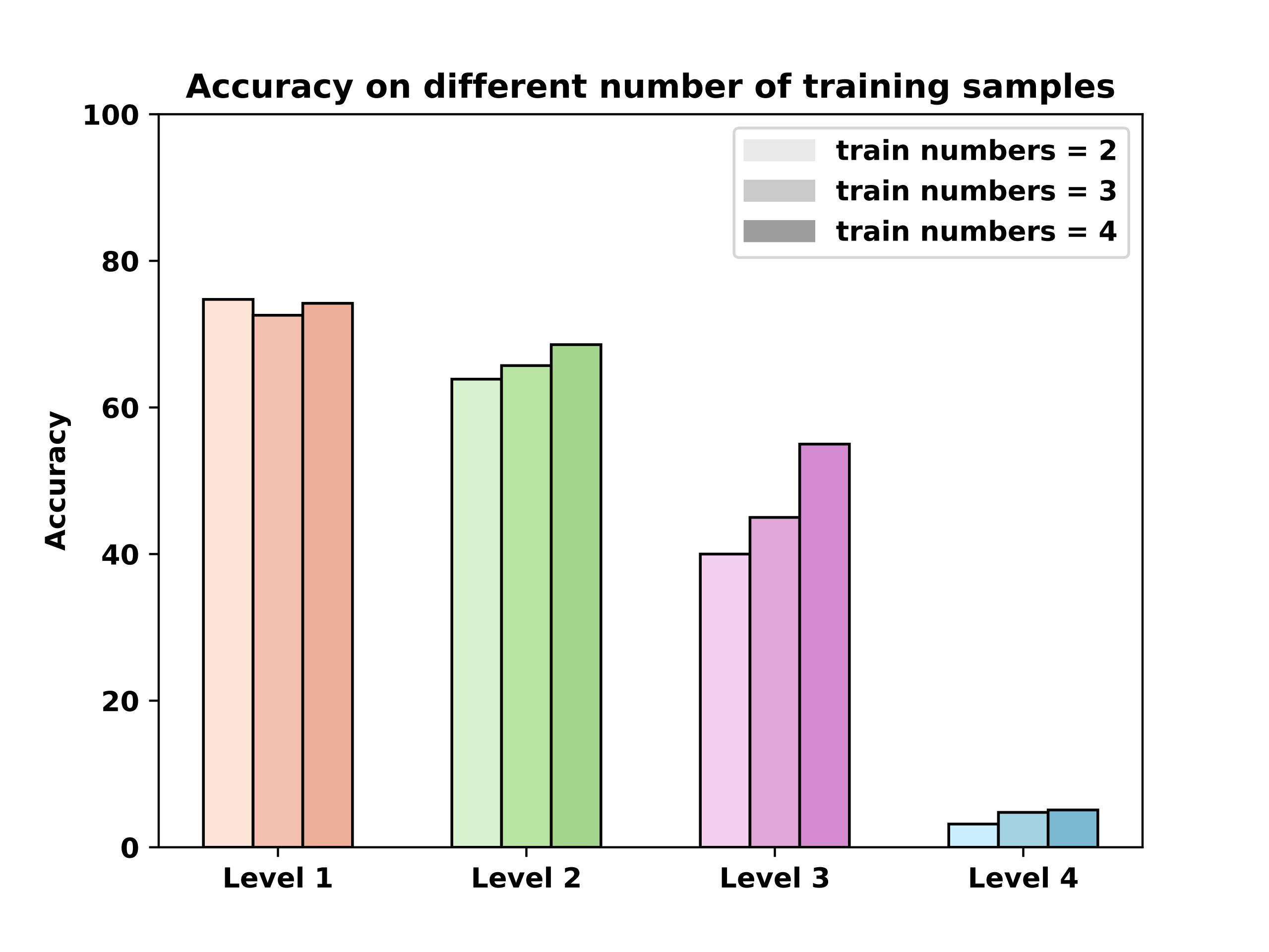
in this section, we evaluate state-of-the-art large language models and investigate the following research questions through experimental results: i) How do current LLMs perform in abstract reasoning across different cognitive levels? ii) As the complexity of dynamic data increases, how will the LLM's performance change? iii) Based on the performance of different LLMs across various cognitive dimensions, to what extent has the model's intelligence level reached? iv) Is inference time scaling, visual information, and number of training context samples, truly effective for abstract reasoning tasks?
_00.png)
_00.png)